Python官方文档:https://docs.python.org/zh-cn/3/
-0-
python常见内置函数
len() #长度
None #空
type() #查看数据类型
format()#格式化
replace()-替换
find()-查找
join(())-拼接
split()-分割
lower()-转小写
upper()-转大写
bool() id() float() int()len() list() str() type() tuple() "{}:{}".format('jack', 300)
res=s.replace('123','999',2)
res=s.find('23',4,10) #从第五开始找
res = ' '.join((s1, s2, s3))
res.strip('+')-1-
一、安装python、pycharm
二、新建项目
三、pycharm设置集合
1.pycharm设置作者信息
2.设置项目解释器-setting-project-齿轮号
四、python package 和普通文件夹区别
python package有init文件
init文件作用:
1.标识该目录是一个python的模块包(module package)
2.简化模块导入操作
-包在被导入时会执行init文件-可放初始化代码
五、输入、输出、数值类型、数值运算符、比较运算符、转义符
#输入-输出
a = input('输出dotcpp的网站:')
b = float(input('我认为适宜的温度:'))
index = list(map(int,input().split()))
#这种方式可以输入任意个int型的数字,在这里采用列表来存储。输入时空格分开
print(index)
print(index[0])
#数值类型
int float bool
c = 9
d =9.9
e = True
数值运算符
+ - * / //取整 %取余
比较运算符
> < >= <= == != is is not
转义符 \
print("children\'s class") #children's class
制表符 \t六、字符串格式化-format
插入字符、格式小数位数、百分位数、长度、填充、不支持反向索引
占位符:%s -任意类型 %d-整数 %f -浮点类型
print("您的体重是:%d" %(33))
#format两种方式,可标序号,可不标序号,从0开始
#format:
desc = "您的姓名是:{0}。您的体重是:{1}。"
name = 'Jack'
weight = 200
print(desc.format(name, weight))
#倒序
desc = "您的姓名是:{1}。您的体重是:{0}。"
#不填序号
print("您的姓名是:{}。您的体重是:{}。".format('jack', 300))
#格式化小数位数-保留两位小数-得到1.75
desc2 = "您的身高是{:.2f}".format(1.755)
#格式化百分数显示-保留两位小数-得到33%
print('通过率为{:.2f}'.format(1/3))
#格式化字符串中的长度
{:<20}占20字符左对齐
{:>20}占20字符右对齐
{:^20}占20字符居中对齐
{:*>20}占20字符右对齐-*号填充空白
字符串的f表达式-3.7版本后
desc = F'您的姓名是:{name}。您的体重是:{weight}。'七、索引、切片-字符串、列表、元组
[:0] [0:1] [0:5:2]
#索引-找单个[:3]-第4个-d
#结果=数据[索引值]
s1 = ‘abcde’
res = s1[2] #正向c-从0开始
res = s1[-1] #反向e-从-1开始
循环打印单个字符串
s1 = 'abcde'
for i in range(len(s1)):
print(s1[i])
i = i+1
#切片-找多个[1:3]-取头不取尾-取第2、3位-bc
#结果=数据[start:end]
#切片2-跨步取值-[0:5:2] -ab cd e -跨两步,得ace
列表:[]
元组:() 不可修改八、替换-replace
s ='123rrr123ttt123'
res=s.replace('123','999',2)
#参数1被参数2替换,替换参数3个,无参数3时全替换
#只能替换字符串型,不能替换数值型九、查找-find-返回第一个位置索引
s ='123rrr123ttt123'
res=s.find('23')
res=s.find('23',4,10) #从第五开始找十、字符串拼接-join(())
s1 = 'Kacy'
s2 = 'Mick'
s3 = 'Judy'
res = ' '.join((s1, s2, s3))
res = '@love@'.join([s1, s2, s3])
print(res)
#Kacy@love@Mick@love@Judy
#字符串的join()方法只能带1个入参,多个字符串用list或元组十一、字符串分割-split()
s5='@Kacy@love@Mick@love@Judy@'
res = s5.split('@')
#得到的是['','Kacy', 'love', 'Mick', 'love', 'Judy', '']
#注意有首尾有空十二、字符串去除前后字符-strip()
#去除前后空白字符
print(res.strip())
#去除前后特定字符
print(res.strip('+'))
#去除左边字符
res.lstrip()
#去除右边字符
res.rstrip()十三、列表的增删改查
li = [123,12]
#添加数据
li.append(111) 结尾处添加元素
li.insert(0,'第一个‘)指定位置添加元素
li.insert(-1,'倒数第二个’)插到倒数第二个 -0,-1
li.extand([123,2232]) 两个列表合并
#删除数据
li.remove(12)删除指定第一个数据
li.pop() 删除指定索引
li.clear() 清空所有数据
#修改数据
li[0]='111'
# 查找数据
li[0] 索引取值
li.index(‘111’)查找元素对应索引
# 字符串查找数据,参数只能是str
‘asd1aas’.index('1')
‘asd1aas’.find('1')
# 统计某元素个数
li.count(1)
# 复制:copy()只复制值
# 列表反序
li.reverse()
li[::-1] 切片反序
#Ctrl查看,如果返回不指向None,使用时需要再建个变量给来接收返回数。如果指向None,直接使用原变量即可
# 将字符串转换成列表-内置函数eval()-去掉最外层格式
li = eval('[11,22]')
# 排序 sort()
li.sort() 升序
li.sort(reverse=True) 降序
#切片:[1,2,3,4,5,6,7,8,9]
[2::3]从第三个切到最后,步长为3
十四、元组()
li=(123,'122')
元组特性:与列表接近、数据不可变十五、字典{}
字典{}:有键值对,列表和元组必须知道序号才可以提取值
li = {'age':18,'name':'jack'} 键不能重复,键只能是数值、字符串、元组等不可变类型数据。多用字符串。
# 增
li = {}
li['sex'] = 'woman'
li.update({'sex':'woman'}) 添加
# 改
li['sex'] = 'woman'
li.update({'sex':'woman'}) 有则改、无则增
# 删
li.pop('name') 删除对应键的值
li.popitem() 删除最后一个键,并以元组形式返回,实际type还是dict
li.clear() 清空
# 查
li['name']
dict.keys() 返回所有键
dict.values() 返回所有值
通常转成列表或元组使用
dict.items() 以元组形式返回键和值
与for循环结合
创建字典:{} dict()
eval() 字符串转字典十六、集合{}
set={11,22,33}
set = set() #定义空集合
集合内没有重复元素
去除列表内重复元素:list-set-list\
li = [1,22,22,33]
a = list(set(li))十七、随机数
import random
res = random.randint(1,999) 随机整数
res = random.random() 随机小数,0-1之间
res = random.uniform(10,20) 10-20之间的小数
li = [1,33,55]
res = random.choice(li) 在列表中挑选一个随机值
十八、条件判断
if elif else
逻辑运算:and or not
成员运算:in ,not in
身份运算:is ,is not 判断内存id
赋值运算:= ,+= ,-= ,*= ,/= ,%=十九、循环
while True:break continue
for i in [1,2,3]/dic/dic.value/dic.items():
元组拆分-遍历键和值:
for k,v in dic.items():
列表循环
li2 = ['www{}'.format(i) for i in range(10)]
li = [ i+1 for i in (11,22,33)]二十、range内置函数
生成指定序列
li = list(range(100))
li = list(range(9,99,2))二十二、函数
1、必备参数 def func(a,b)
2、默认参数 def func(a=11,b=22)
3、不定长参数 def func(*args)
*args只能位置传参
**kwargs 只能使用关键字传参
4、函数拆包-*可以对列表或元组拆包,**可以对字典拆包
func(*[11,22,33])
for i,v in enumerate li:
print(i,v)
5、lambda 函数
func = lambda x: 2*x
6、min(li) max(li) sum(li)
7、eval(‘1+22’)识别表达式
8、enumerate 获取列表中的数据及索引
9、zip 数据聚合打包
title =['name','sex']
data =[‘张三’,‘女’]
res=zip(title,data)
10、filter 过滤函数
res= filter(lambda x:x>80,stu)
11、自定义排序规则sort(key=)
li.sort(key=func)
li.sort(key=lambda x:x[2])二十三、文件操作和模块导入
f = open(file='biji.txt',mode='r',encoding='utf-8')
mode =r/w/a(追加、自动创建文件) rb wb ab 以二进制读取 +可读可写
f.read()
f.readline()
f.readlines() ->list
f.write()
f.close()
with open(file ='',mode='rb') as f: 自动关闭
res=f.read()二十四、相对路径、绝对路径
1、绝对路径 C:\Users\A80\Desktop\需求\WMS
2、相对路径 .当前层级 .. 上个层级
3、文件路径转义 file=r‘C:\Users\A80\Desktop\需求\WMS’ 加r关闭转义二十五、模块和包
模块:python文件
包:python文件夹 有init文件
导入模块
from src/ss import SS
导入包
import requests
from requests import session
只直接运行此文件时成立
if __name__ == "__main__":
import sys (所有可用包)二十六、异常
自定义异常类型:
class TooLongExceptin(Exception):
"this is user's Exception for check the length of name "
def __init__(self,leng):
self.leng = leng
def __str__(self):
return "姓名长度是"+str(self.leng)+",超过长度了"
try:
name = "1111"
print("1")
if len(name) > 2:
raise TooLongExceptin(leng=len(name))
raise ValueError("只能小于2")
except Exception as e:
print(e)
else:
print("没报错")
finally:
print("还是要执行")
常用异常类型:
https://blog.csdn.net/csdnbian/article/details/113447496二十七、类和对象
1、属性:
类属性(共有)、类名.属性名=属性值
对象/实例(独有)属性 对象.属性名=属性值
class Cat:
leg= 4 类属性
cat = Cat()
cat.name = 55 实例属性
2、方法
实例方法:self代表对象本身,没有self,无法使用对象调用方法,只能使用类调用
class Cat:
def func(self):
print(1)
类方法
@classmethod
def func(cls,name=‘’): cls代表类本身,可以类调用,也可以对象调用 里面不要用self.name实例属性
静态方法
@staticmehod
def func()内部不使用类属性和类方法,也不使用对象属性和时
初始化方法 def __init__(self,name='',age=''): 通过类创建对象时自动调用二十八、继承和属性动态操作
1、私有属性:__attr只能在类内使用、 _attr表示私有,实际类外部能调用
2、私有方法:def __attr(),def _attr()
3、继承
重写:同名方法,优先子类、私有属性不继承
拓展父类:在子类调用父类方法super.func(),
class Father:
def __init__(self,name):
self.name=name
class Child(Father):
def __init__(self,name,price):
Father.__init__(self,name) 或者 super().__init__()
self.price=price
4、动态属性 内置方法 用于属性是字符串时 如 "age"="18"
MyClass.__dict__ 显示类所有相关属性
设置属性setattr(MyClass,key,value) 获取getattr(MyClass,key)
删除delattr(MyClass,key) 判断属性是否存在hasattr(MyClass,key)
例:把字典中的键值对设置为类属性和属性值
data = {"name":"muse',"age":"18"}
for k,v in data.items():
set(MyClass,k,v)
5、常用关键字
del li[3] del dic['b']二十九、unittest的使用
1、测试用例类必须继承unittest.TestCase
class TestLogin(unittest.TestCase):
2、test开头方法为测试用例、使用实例方法
3、编写测试用例
1)准备用例数据
2)调用被测功能函数
3)断言
4、编写主运行文件 run.py
import unittest
# 创建套件
suite = unittest.TestSuite()
# 创建用例加载器
load = unittest.TestLoader()
# 加载用例套件
suite.addTest(load.discover(r'文件路径'))
~~替代
suite = unittest.defaultTestLoader.discover(r'F:\file\src\news')
# 创建测试用例运行程序
runner =unittest.TextTestRunner()
# 运行测试用例
runner.run(suite)
5、测试用例生成报告 run_report.py pip3 install unittestreport
https://pypi.org/ 官方查找拓展包及其使用方法
6、TestFixture 前置方法、后置方法
def setUp(self) def tearDown(self) 方法级别,每个测试方法都运行
@classmethod 类级别
def setUpClass(cls) def tearDownClass(cls)
7、断言方法
self.assertEqual(a,b)
self.assertIn('成功','成功了')
assert a ==b
8、测试用例路径
# file = 'test_jtyoui.py'
# case_path = os.path.join(os.getcwd(), "testsuite")
# case_path = os.path.join(os.path.dirname(os.path.abspath(file)))
suite = unittest.defaultTestLoader.discover(case_path)三十、ddt的使用和excel的数据读取
# ddt使用步骤
# 1.测试类前使用@ddt
# 2.在测试方法前使用@list_ddt(测试数据)
# 3.在测试方法中定义一个参数,用于接受用例数据|
# install
import unittest
from ddt import ddt,list_data
#from unittestreport import import ddt,list_data
@ddt
class TestMusen(unittest.TestCase):
@list_data([1,2,3])
def test(self, item):
print(item)# excel的使用
# Excel使用xlsx格式,解析成三个对象,工作簿workbook、表单Sheet、单元格Cell
import openpyxl
workbook = openpyxl.load_workbook('test1.xlsx')
print(workbook.sheetnames)
sh = workbook['Sheet1']
print(sh.cell(row=3,column=3).value)
#按行读取 rows 按列读取 column
res = list(sh.rows)
for i in res:
print(i,i.value)
# 转为字典格式
res = list(sh.rows)
title = [i.value for i in res[0]]
cases = []
for item in res[1:]:
data = [i.value for i in item]
dic = dict(zip(title,data))
print(dic)
cases.append(dic)
@ddt
class TestMusen(unittset.TestCase)
@list_data(cases)
def test(self, item):
expected = eval(item['espected'])
params = eval(item['data'])
res = func(**params)
self.assertEqual(expectet,res)
# 结果
{'case':'1','data':'2','expected:'3'}
{'case':'1','data':'2','expected:'3'} # 封装Excel
import openpyxl
class HandleExcel:
def __init__(self,filename,sheetname):
self.filename = filename
self.sheetname = sheetname
self.workbook = openpyxl.load_workbook(filename)
self.sheet = self.workbook[sheetname]
def read_data(self):
res = list(self.sheet.rows)
title = [i.value for i in res[0]]
cases = []
for item in res[1:]:
data = [i.value for i in item]
dic = dict(zip(title, data))
cases.append(dic)
return cases
def write_data(self,row_no:int,colunm_no:int,value):
self.sheet.cell(row=row_no,column=colunm_no,value=value)
self.workbook.save(filename=self.filename)
@ddt
class TestMusen(unittest.TestCase):
excel = HandleExcel('仓库作业-入库.xlsx', 'Sheet1')
cases = excel.read_data()
@list_data(cases)
def test(self, item):
expected = eval(item['expected'])
params = eval(item['params'])
res = func(**params)
self.assertEqual(True, res)#run.py
import unittest
import os
if __name__ == '__main__':
# file = 'test_jtyoui.py'
# case_path = os.path.join(os.getcwd(), "testsuite")
# case_path = os.path.join(os.path.dirname(os.path.abspath(file)))
# print(case_path)
suite = unittest.defaultTestLoader.discover(r'F:\file\src\news')
# 创建测试用例运行程序
runner = unittest.TextTestRunner()
# 运行测试用例
runner.run(suite)三十一、日志输出
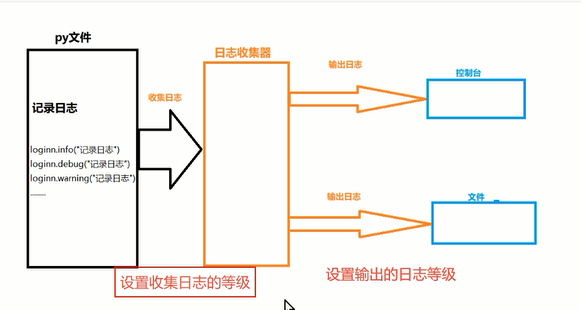
# -*- coding: utf-8 -*-
"""
@Time : 2022/10/28 17:34
@Auth : dengyunman
@File :log.py
"""
import logging
def create_log(name='mylog',level="DEBUG",filename='log,log',sh_level='DEBUG',fh_level='DEBUG'):
# 1、创建日志收集器
log = logging.getLogger(name)
# 2、设置日志收集器的收集等级
log.setLevel(level)
# 3、设置输出渠道
# 3.1 输出到文件
fh = logging.FileHandler(filename,encoding='utf-8')
fh.setLevel(fh_level)
log.addHandler(fh)
# 3.2 输出到控制台
sh = logging.StreamHandler()
sh.setLevel(sh_level)
log.addHandler(sh)
# 4、设置输出格式
log_format = logging.Formatter('%(asctime)s--%(filename)s-%(levelno)s:%(message)s')
sh.setFormatter(log_format)
fh.setFormatter(log_format)
return log
mylog = create_log()
log = create_log()
log.debug("---debug---")
log.info("---info---")
log.warning("---warning---")
log.error("---error---")
log.critical("---critical---")test.py
from log import mylog
mylog.error("---error---")三十二、配置文件
ini文件格式: .ini 配置工具ini -settings -plugins -ini搜索安装
ini.ini
[logging]
level = DEBUG
file = log.log
sh_level = info
[mysql]
host = 127.0.0.1
port = 3306
username = root
password = root
name1 = dengini操作-读取 写入(少用)
from configparser import ConfigParser
# 1.创建配置文件解析器对象
cp = ConfigParser()
# 2.读取配置文件内容到配置文件解析器中
cp.read('ini.ini', encoding='utf-8')
# 3.读取配置内容
res = cp.get('logging', 'file')
print(res)
# cp.getint()
# cp.getboolean()
# cp.getfloat()
# 写入
cp.set('mysql','name1','deng')
cp.write(fp=open('ini.ini','w',encoding='utf-8'))yaml文件格式 .yaml 配置工具yaml -settings -plugins -yaml搜索安装
pip3 insatll pyyaml
yaml.yaml
# yaml文件读取出来不是列表就是字典|最外层要统一为列表或统一为字典
# 字典 冒号后面必加空格
# 嵌套字典
case:
data:
user: jack
pwd: pass
expected:
msg: 通过
# 列表
list:
- 1
- 2readyaml.py
import yaml
with open('yaml.yaml','r',encoding='utf-8') as f:
res =yaml.load(f,Loader=yaml.Loader)
print(res,type(res))
print(res['case']['data'])三十三、json数据
json.json
{
"?mysql": "json文件字段必加双引号",
"mysql": {
"name": "jack",
"pwd": "root",
"gender": "女",
"habits":["football","tennis"],
"is18+":true,
"rings": "None"
}
}readjson.py
import json
with open("json.json",'r',encoding='utf-8') as f:
res =json.load(f)
print(res,type(res))
print(res['mysql']['is18+'],type(res['mysql']['is18+']))
# ---------------json转python---------------
# 将json字符串转为python数据
run = '{"aa":true,"bb":null}'
pydata = json.loads(run)
# ---------------python转json---------------
# 将python数据(列表或字典)转换为json -变为str类型
dic = {"mysql": {
"name": "jack",
"pwd": "root",
"gender": "女",
"habits":["football","tennis"],
"is18+": True,
"rings": None
}}
# 变为str类型
json_res =json.dumps(dic)三十四、综合应用
项目结构:
用例数据文件 --->datas
日志文件 ---->logs
测试报告 ---->reports
配置文件 ---->conf
测试用例模块 ---->cases
封装的公共模块---->common
封装的读取、操作excel的模块
封装的读取创建日志收集器的模块
项目运行启动模块
发表评论